Кількість цифрових покупців зростає протягом останніх кількох десятиліть, і навіть пандемія COVID-19 не перервала цю тенденцію. Насправді ізоляція та політика соціального дистанціювання лише сприяли різкому зростанню покупок в Інтернеті. У 2020 році кількість цифрових покупців перевищила два мільярди людей, а продажі електронної роздрібної торгівлі перевищили 4,2 трильйона доларів у всьому світі.
Експерти прогнозують, що світовий ринок електронної комерції розшириться на 1 трильйон доларів до 2025 року. Це означає, що на ринок вийде більше нових компаній електронної роздрібної торгівлі, а конкуренція між компаніями на ринку стане ще сильнішою.
Що слід зробити роздрібним Інтернет-магазинам, щоб утримати свої компанії на плаву в довгостроковій перспективі? Їм слід переглянути та оновити свою цінову політику, щоб одним пострілом вбити двох зайців: максимізувати прибутковість та завоювати лояльність клієнтів.
Як вони можуть це зробити? Одним зі способів це зробити є використання навчання з підкріпленням для динамічного ціноутворення.
Сьогодні ми поговоримо про навчання з підкріпленням, динамічне ціноутворення та про те, як це допомагає ритейлерам йти в ногу зі змінами цін.
Концепція динамічного ціноутворення
Перш ніж заглибитися у цю тему, визначмось із терміном динамічне ціноутворення та пояснимо, чим ця стратегія відрізняється від статичного ціноутворення.
У стратегії статичного ціноутворення ціна залишається незмінною протягом тривалого проміжку часу. При динамічному ціноутворенні ціна зростає та опускається залежно від попиту (та інших ринкових факторів) в певний момент.
Коли застосовується динамічне ціноутворення, система змінює ціну на товари та послуги в режимі реального часу, щоб максимізувати дохід ритейлера та покращити ключові показники ефективності, такі як середня вартість угоди та коефіцієнт конверсії.
Як система знаходить «оптимальну ціну»? Система відстежує зміни ринкових позицій та коригує ціну на основі таких параметрів:
-
Попередня та поточна ціна товару
-
Попередні та поточні ціни конкурентів
-
Зміни в уподобаннях споживачів
-
Зміни в покупній поведінці цільової аудиторії
-
Час (час доби, пора року тощо)
Як динамічне ціноутворення може допомогти ритейлерам?
Ключова перевага динамічного ціноутворення полягає в тому, що воно дозволяє ритейлерам швидко аналізувати тенденції ринку та визначати «правильну ціну» на товар.
Що таке «правильна ціна»? Це ціна, яка задовольняє покупців цієї миті та при цьому дозволяє ритейлерам отримати максимальний прибуток.
Хто може отримати вигоду від динамічного ціноутворення?
Стратегія динамічного ціноутворення не є чимось новим. Авіакомпанії, компанії з прокату автомобілів, готелі, залізничні компанії та концертні майданчики роками використовують стратегії динамічного ціноутворення, щоб адаптувати свій бізнес до мінливих ринкових умов та випередити конкурентів.
Uber та модель динамічного ціноутворення
Uber ̶ одна з тих компаній, які застосовують динамічну модель ціноутворення. Якщо ви давно користуєтесь Uber, ви знаєте, що вартість вашої поїздки залежить не тільки від відстані вашої поїздки, але і від погодних умов, поточного рівня попиту та інших факторів.
Розглянемо приклад. Уявіть собі, що звичайний тариф поїздки Uber «Дім ̶ Аеропорт» становить 30 доларів. Якщо ви їдете в аеропорт у п’ятницю в годину пік (час підвищеного попиту), вам доведеться заплатити вищу ціну (близько 40 доларів). А якщо йде сильний дощ, вартість вашої поїздки зросте ще більше ̶ вам доведеться заплатити близько 50 доларів, щоб вчасно дістатися до аеропорту. Ось в чому суть динамічного ціноутворення ̶ як користувач Uber, ви можете погодитися заплатити більше та отримати послугу негайно, а можете почекати, поки ціни знизяться.
Попри те, що більшість клієнтів мають негативне ставлення до стрибкоподібного ціноутворення та високих тарифів, система динамічного ціноутворення виявилася високоефективною. Експерти з Economist порівняли середній час, необхідний для замовлення Uber у разі зростання попиту: а) коли система НЕ працює та б) коли система працює.
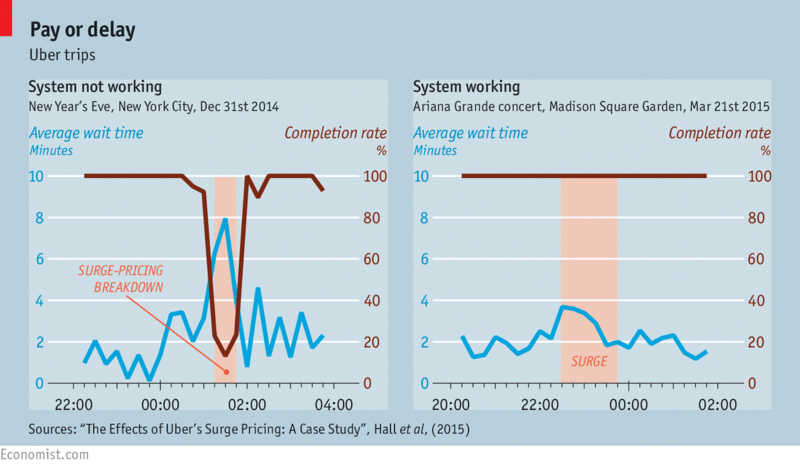
Джерело зображення: economist.com
Вони з’ясували, що середній час очікування різко збільшується, коли система НЕ працює, а відсоток виконання замовлень падає. А коли система працює, ситуація інша. Швидкість виконання замовлення складає 100%, а середній час очікування не сильно збільшується, навіть у самі завантажені години. Це означає, що загальна задоволеність клієнтів залишається високою, а компанія продовжує виконувати замовлення та заробляти гроші без істотних збоїв.
Чому ви повинні розглянути можливість використання динамічного ціноутворення для вашого бізнесу електронної комерції?
Якщо ви хочете залишатися конкурентоспроможними на постійно мінливому ринку, вам слід використовувати гнучку модель ціноутворення. Ви повинні коригувати ціни так швидко, як тільки з'являються нові тенденції.
Якщо ви виберете стратегію динамічного ціноутворення, ви отримаєте конкурентну перевагу. Вам буде легко визначити для продукту піковий та низький сезони. Ви будете знати, коли саме вам слід знизити ціну, щоб збільшити продажі, а коли можна підвищити ціни, не ризикуючи втратити своїх клієнтів.
Дослідники стверджують, що динамічне ціноутворення може збільшити доходи та прибуток відповідно до 8% та 25%. Однак все залежить від розміру ринку та кількості угод. Чим більший ринок, на якому ви працюєте, тим більшою є можливість максимізації прибутку.
Ще одна велика перевага впровадження стратегії динамічного ціноутворення полягає в тому, що вона дозволяє отримати глибоку інформацію про ринок. Ви можете краще зрозуміти зміни у поведінці споживачів та приймати більш обґрунтовані стратегічні рішення у короткостроковій та довгостроковій перспективі.
Динамічне ціноутворення та світ електронної комерції: проблеми та можливості
Попри те, що динамічне ціноутворення має масу переваг, воно також має один специфічний недолік ̶ ніколи не знаєш, як споживачі відреагують на зміну ціни. Коли ціна різко зростає, завжди існує ризик втратити лояльність своїх клієнтів.
Вище ми розглянули приклад, коли вартість поїздки в Uber зросла з 30 до 50 доларів через високий попит та погані погодні умови. Це приклад динамічної зміни цін, з якою більшість клієнтів може змиритися.
Однак є й інші ситуації, коли використання динамічної цінової стратегії призводить до більш значного росту цін. Наприклад, у 2016 році напередодні Нового року ціни на Uber у Сіднеї зросли на 800%.
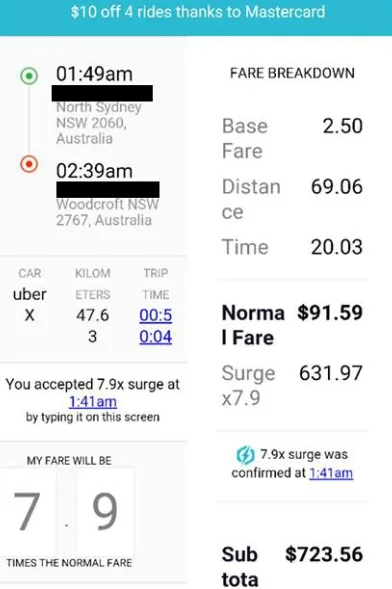
Джерело зображення: smh.com.au
Ця ситуація негативно вплинула на репутацію Uber. Багато користувачів, які переплатили за свої поїздки, поклялися більше ніколи не користуватися додатком.
Іншими словами, використовуючи динамічне ціноутворення, ви не зможете подолати невизначеність реакції клієнтів. Щоб розв'язати цю проблему, потрібно більш розумно використовувати дані про продажі.
Що таке "дані продажів"? Дані про продажі це послідовність точок даних (цін), індексованих в часовому порядку. Вони включають інформацію про ціни на продукцію, доходи та інші змінні, які впливають на продажі (товарний запас, ціни, встановлені конкурентами, технологічні тенденції, тенденції моди, сезонність тощо).
Дані про продажі роблять свій внесок. Це інформація, необхідна ритейлерам для розробки ефективного програмного забезпечення динамічного ціноутворення.
Варто підкреслити той факт, що вимірювання ефективності роботи агентів в реальному житті є складним завданням. З цієї причини, далі, ми розглянемо вигаданий приклад, а не приклад із реального життя.
Яку модель прогнозування продажів ми будемо використовувати? Ми зупинимо свій вибір на моделі, де стан ринку вважається «вхідним», а прогнозовані продажі ̶ «вихідними». Ціна буде розглядатися як окрема незалежна змінна.
Як ми навчимо агентів знаходити оптимальну стратегію ціноутворення? Ми будемо використовувати комплексний підхід. Ми будемо застосовувати передові методи машинного навчання та використовувати великі дані (дані продажів) для прогнозування часових рядів.
Моделі прогнозування: два альтернативні підходи для пошуку правильного рішення та побудови виграшної стратегії ціноутворення
Для визначення цінової стратегії ми можемо використовувати два методи: простий та складний.
Почнемо з простого - підходу одноетапної оптимізації. Ось як працює ця модель прогнозування: ми встановлюємо різні ціни (високі ціни, низькі ціни та будь-які випадкові ціни) та аналізуємо, як вони впливають на наш рівень рентабельності.
Що ще ми повинні знати про модель прогнозування? Ми можемо визначити цю модель як непараметричну модель, в якій розподіл даних не може бути визначений в параметрах кінцевого набору. Це означає, що ми не можемо застосувати до цієї моделі методи оптимізації на основі градієнта.
Натомість ми можемо кодувати безперервні атрибути в дискретні та перетворювати їх на злічувані числа ̶ можливі ціни. Це дозволить нам вибрати ціну, пов'язану з найбільшим потенційним доходом, або досягти іншої мети.
Які плюси цього методу? Використовуючи цей метод, ми уникаємо потрапляння в пастку «локального мінімуму».
Які мінуси цього методу? Цей спосіб жадібний. Він дозволяє нам максимізувати дохід прямо тут і зараз, але не допомагає накопичувати дохід. Простою мовою, цей підхід може допомогти електронним ритейлерам збільшити свій дохід у короткостроковій перспективі, але не допоможе їм максимізувати прибуток у довгостроковій перспективі.
Який найкращий альтернативний підхід до динамічного ціноутворення? Який метод може допомогти ритейлерам тримати жадібний алгоритм під контролем? Найкращим альтернативним рішенням є навчання з підкріпленням (Reinforcement Learning (RL)).
RL здатний виявити взаємозв'язок між послідовними етапами ціноутворення. Що це означає? RL не жадібний до поточних продажів. Однак, він жадібний до накопичення прибутку.
Наприклад, навчання з підкріпленням може визначити момент часу, коли ритейлери повинні знижувати ціни та отримувати нижчий дохід у короткостроковій перспективі, щоб отримати більший дохід після зміни ринкових умов.
Основи навчання з підкріпленням
Що таке навчання з підкріпленням? Це метод машинного навчання, який заснований на винагороді за бажану поведінку. Розробники програмного забезпечення використовують RL для написання алгоритмів, спрямованих на максимізацію накопичення прибутку. Ці алгоритми застосовуються до агентів, які досліджують невідоме середовище.
Тепер вам може бути цікаво, як ми можемо описати середовище. Нам потрібно застосувати Марківський процес вирішення (MDP), математичну структуру, яка представляє середовище навчання з підкріпленням. Це структура, в якій агент може розігрувати різні сценарії та впливати на результати.
Далі, ми будемо використовувати MDP з кінцевим горизонтом. Ось формула:
p (s', r ∣ s, a) = P (St = s', Rt = r | St - 1 = s, At - 1 = a)
∑s ′ ∈S ∑ r∈S p (s', r ∣ s, a) = 1, де s ∈ S, a ∈ A
Ось елементи формули:
-
S простір стану (скінченна множина)
-
An простір дій (скінченна множина)
-
R простір винагороди (підмножина дійсних чисел, кінцева множина)
-
p функція динаміки (визначає динаміку MDP)
Тепер вам може бути цікаво, як агенти взаємодіють із середовищем (MDP). Існує одна взаємодія в кожний момент часу: t = 0, 1, 2 тощо.
Ось як можна описати цей процес: агент робить крок (дія “а”), сама дія є похідною від “s” (поточних ринкових умов). MDP вибирає дію "а" та реагує на неї винагородою "r" ̶ далі вона випадковим чином переходить у новий стан "s" і надає особі, яка приймає рішення, відповідну винагороду "R".
Ось як виглядає ця послідовність:
S0, A0, R1, S1, A1, R2, S2, A2, R3,...
Погляньте на наступну візуалізацію взаємодії агента з середовищем в MDP.
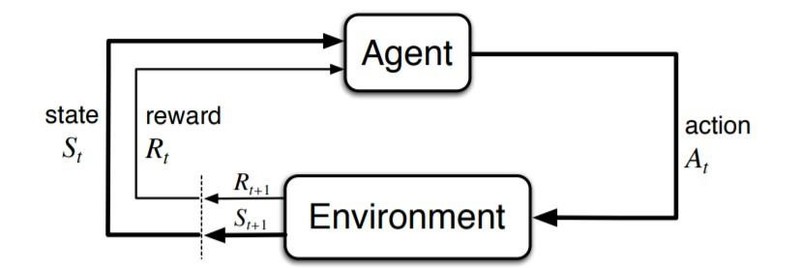
Джерело зображення: towardsdatascience.com
Як ми вже згадували, ключовою метою навчання з підкріпленням є підвищення рівня кумулятивного доходу, який агент в кінцевому підсумку очікує отримати (гіпотеза винагороди). Тепер ми повинні визначити прибуток як функцію винагороди. Якщо розглядати епізодичні завдання (завдання, виконання яких припиняється), то функція буде такою:
Gt = Rt + 1 + Rt + 2 + Rt + 3 + ... + RT
Тепер розгляньмо функцію політики, яка описує процес MDP.
π (a∣s) = P (At = a∣St = s)
Далі, ми повинні визначити дві функції: перша ̶ це значення стану, а друга ̶ дія-значення. Ці функції демонструють обсяг кумулятивного доходу, який ритейлер може отримати в стані, який визначається як "s" під час виконання "а", призначеної дії:
vπ (s) = Eπ [Gt ∣St = s]
qπ (s, a) = Eπ [Gt ∣St = s, At = a]
Відповідно до цієї теорії, існує мінімум одна політика, визначена як «оптимальна» у даному середовищі. Ця політика має найвищу цінність щодо усіх можливих станів. І це ключовий момент алгоритму RL ̶ він завжди прагне наблизитися до оптимального рішення.
Застосування навчання з підкріпленням та розв'язання задач динамічного ціноутворення
Коли ми говоримо про динамічне ціноутворення та його переваги, ми очікуємо, що агент проаналізує поточні тенденції на ринку та знайде оптимальне цінове рішення. А що ми вважаємо “діями”, пов’язаними з RL? Дії ̶ це набір усіх можливих цін, станів та ринкових умов, за винятком поточної ціни товару.
У більшості випадків складно провести вибіркове навчання агентів RL з цілями для реальних завдань. Агентам потрібно занадто багато часу та зусиль для збору великої кількості даних про продажі.
Крім того, агенти стикаються з компромісом дослідження та експлуатації ̶ фундаментальною дилемою: дізнатися більше про світ, випробовуючи речі на практиці. Дилема полягає в ухваленні рішень з отриманням результатів близьких до очікуваних ("експлуатація"), і вибором того, у чому ви не впевнені, і, можливо, дізнатися більше ("дослідження"). Іноді це змушує агента діяти так, що це призводить до значних фінансових втрат для компанії.
Щоб заощадити час та гроші, агентам необхідно обрати альтернативне рішення. Вони повинні використовувати імітовані дані, а не дані реального світу. Єдине складне завдання тут ̶ відтворити переходи, які показують, як стани змінюють одне одного. Імітувати зміну ринкових умов не так просто, але є один спосіб змусити цю стратегію працювати.
Табличне Q-навчання
Одним словом, табличне Q-навчання ̶ це алгоритм навчання з підкріпленням без моделі. Погляньте на його основну формулу:
Q*(s, a) = maxπ Eπ [Gt∣St = s, At = a]
Знаючи цю формулу та значення призначених дій, агенти можуть отримати оптимальне рішення щодо ціноутворення. В принципі, це може бути будь-яка політика, визначена як «жадібна». Ось оновлена формула для використання:
Q (St, At) ← Q (St, At)+α [Rt+1+γ*maxaQ (St, a) - Q (St, At)]
Q-функція використовує рівняння Беллмана і приймає два входи: стан та дію. Процес оновлення значень можна охарактеризувати як ітераційний. Коли агент починає досліджувати навколишнє середовище, Q-функція дає все кращі наближення, постійно оновлюючи Q-значення.
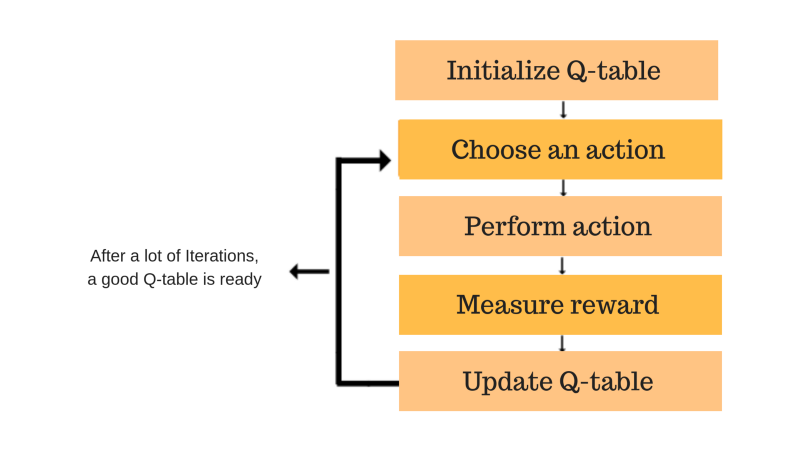
Джерело зображення: freecodecamp.org
Перше, що вам потрібно зробити, щоб запустити цей алгоритм, ̶ це розділити дані ̶ перетворити безперервні змінні в дискретну форму. Як бачите, назва цього алгоритму містить слово «табличний». Це означає, що система зберігає всі значення дій в одній величезній таблиці.
Звичайно, що чим більше функцій і змінних додано до таблиці, тим більше збільшується час навчання та обсяг пам’яті. Це причина, чому табличне Q-навчання не працює у складних середовищах.
Глибока Q-мережа (DQN)
Наступний алгоритм, який ми розглянемо, ̶ це глибока Q-мережа (DQN). Цей алгоритм дуже схожий на алгоритм Q-навчання, який ми обговорювали вище. Однак є одна істотна відмінність. На відміну від Q-навчання, DQN використовує параметризовану оптимізацію функції значення.
Цей алгоритм машинного навчання застосовує ANN, штучні нейронні мережі, які працюють як апроксиматори.
Q (s, a; θ) ≈ Q*(s, a)
Які переваги глибокої Q-мережі? Вона може працювати з високорозмірними даними, включаючи зображення. Крім того, цей алгоритм виявився ефективним при використанні поза політичної вибірки. DQN дозволяє нам використовувати одну обрану вибірку кілька разів і скористатися досвідом повторного відтворення.
Градієнти політики
Тепер поговоримо про алгоритм, який лежить в основі градієнтів політики. Цей алгоритм передбачає абсолютно інший підхід для отримання оптимальної ціни. Градієнти політики не зосереджуються на пошуку дій з найкращими цінностями, і це не демонструє жадібної поведінки. Натомість цей алгоритм машинного навчання безпосередньо параметризує та оптимізує політику.
π (a∣s, θ) = P (At = a∣St = s, θt = θ)
Градієнти політики працюють набагато краще, ніж жадібний агент, але по ефективності не можуть зрівнятись з глибокою Q-мережею. Якщо ви вирішили використовувати градієнти політики замість DQN, вам доведеться використовувати більше зразків епізодів для оновлення параметра політики θ.
На закінчення
Ви можете бути впевнені, що при використанні навчання з підкріпленням у своєму бізнесі електронної комерції, ви подолаєте проблеми динамічного ціноутворення. Ви отримаєте максимальний прибуток і випередите конкурентів.
Просто майте на увазі, якщо ви реалізуєте цю стратегію, ви повинні бути прозорими у своїх діях по відношенню щодо цільової аудиторії. Ви повинні завчасно повідомити людей про можливі зміни цін, щоб запобігти непорозумінням та зберегти лояльність ваших клієнтів.