Businesses generate more data now than they did only a few years ago. Thanks to cloud computing and AI, many businesses have come to realize that proper data lifecycle management is essential for long-term success.
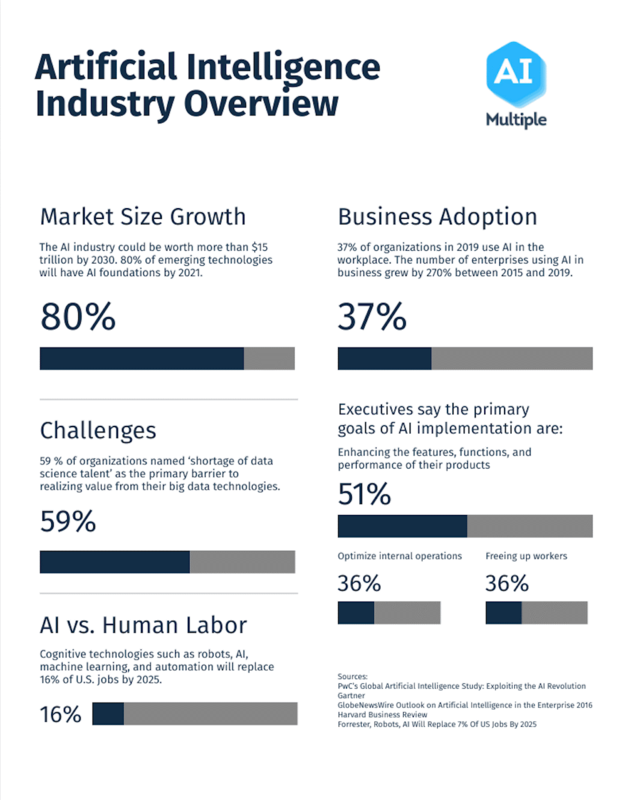
Recent studies have shown that fully outsourced data management will fall by 48% by 2022, with 57% of businesses underutilizing their data due to misinterpretations. Forgoing manual data management and opting for automatization and AI algorithms have proven fruitful for many corporate entities.
Additional research has indicated that 85% of organizations are constantly evaluating AI implementation due to COVID-19 travel and social distancing restrictions. The solution to fully utilizing your business’ available data lies in proper project planning and resource scaling. Understanding the scope of upcoming projects and defining what you need to get them done will enable you to acquire the right technologies on time.
The following steps aim to properly illustrate how a modern data science project based on proper data management should look like. By utilizing these guidelines, you will maximize your business’ data management workflow and ensure that the final products are of a significantly higher quality.
Understanding the Value of Data-Driven Project Life Cycle
Developing new projects and piloting new products and services takes time and resources. Both of those elements are precious for businesses that cannot afford to fail or lag behind the competition.
Recent statistics have indicated that AI, combined with big data, can automate 70% of data processing and 64% of data collection operations. Integrating new technology, combined with a redefined data science project life cycle, can help your business break new ground in the industry.
AI is already in active use across multiple industries and niches, including IT, marketing, production, and HR. Data science and data-driven projects can benefit from using such technology greatly to augment the work done by data analysts and data specialists. The values of relying on a data science project life cycle model include, among others:
-
Use and reuse available data to make informed development decisions
-
Improved marketability and utility of the produced project
-
Increased impact of the final product on the market
-
Improved data storage and indexing for future data-driven projects
-
Higher return on investment and sales generated by the launched product
-
Planning and Brainstorming
Defining what the role of your project will be should always be the first step in your development life cycle. To develop a solid development plan, you need to think about how your product will affect the market and its users. Which problems will it address, and how does data science fit into it? You can answer these questions by researching your market and vetting your competition.
What kinds of products and services based on data management are already in circulation? How can you meet client demands with a unique, utilitarian new product? Assemble an in-house team that will subsequently develop the app or service to get started on the planning stage of your life cycle.
Creating a team for your project will provide the workflow with a foundation for future operations and allow individuals to acquaint themselves with the project. At this point, you will also realize whether any of your development operations require outsourcing or hiring additional staff with specific skillsets.
-
Software Development Life Cycle (SLDC) Secondaries
Once your planning phase is underway, several other activities should be addressed before the project moves into full production. Aligning your in-house teams or specialists is important from the get-go to avoid miscommunication and unnecessary deadline breaches. As part of your software development life cycle, you should cover the following:
-
Assigning a product designer to the project
-
Assigning one or more software developers
-
Assembling a quality assurance (QA) team
With these elements in place, your SLDC will be smoother and less prone to errors. It’s pivotal that all of your staff communicates from the beginning and is aligned toward the same deliverables.
For example, your product designer should create a UI for the data science team to utilize once their back-end development is done with software developers. The quality assurance team should constantly test the product and report bugs and errors to the development team without exception.
Testing should be done throughout the development life cycle to ensure a smooth launch once the bulk of the project is close to completion. This type of DevOps environment will be much more efficient and produce higher quality work than splintered teams ever could.
-
Business Strategy Development
Knowing what type of data is available during project development is critical. Whichever types of data you utilize during development, it’s important to align it with your business goals and needs at that time. Data scientists who spend time analyzing data points often don’t have the business perspective in mind.
This is why setting concrete KPIs for your project can help steer your staff in the right direction. KPIs can be set via SMART methodology, which is perfect for setting achievable, objective, time-oriented goals. This can be done in several steps:
Momentary project analysis – Data scientists should take extra care to review and gauge the staff’s performance, potential issues, and opportunities with the available data. This will help them prioritize and manage the deliverable deadline more realistically.
Project goal-setting – The goals of your project should always align with existing business goals. This will ensure that the existing workflow model is used as much as possible, which will speed up development and reduce initial downtime.
Data model strategy development – Depending on the data which is available to a company, a data utilization strategy should be created for long-term application.
Roadmap development – With these steps covered, data scientists can create a realistic, achievable roadmap for the project at hand. These should always be broken up into larger goals and smaller milestones to be pursued by individual specialists on the staff.
The role of going through these steps is to ensure that the problem which was outlined in step 1 is achievable with available resources. By analyzing available data resources, data scientists can adjust the life cycle model and recommend improvements before full production is underway.
-
Generated Data Utilization
Smart and effective data utilization is pivotal for successful projects to be developed by your staff. With the previous steps serving to prepare the groundwork for your project, data scientists can advise your teams on how to use data more precisely. To train the data science model you need for your project, more new data will be necessary.
That data can be generated by following through on the previous steps we’ve outlined in the life cycle model. In conjunction with your business goals, this will serve as the primary decision-maker for your data scientists in determining how to utilize said data.
Not all data which your project teams generate will be useful, however, and bad data needs to be identified before it is implemented. The following indicators should allow your data analysts to separate bad data going forward:
-
The data didn’t originate from your staff and needs additional vetting before being implemented
-
The data isn’t relevant to the project the team is working on and would slow down their workflow
-
The data cannot be normalized and features missing variables, making its implementation difficult
Data which meets any of these factors will be troublesome for your life cycle model and should be either fixed or eliminated. But what types of data can you consider valid for project development in the first place?
-
Data logs
-
Datasets containing images, audio, and video
-
Manufacturing data
-
Supply chain logs
-
Customer or market data
-
Past financial performance data
Depending on the type of project you are developing, some of the data points may take more time to analyze than others. Different data will cost different time and resources to collect, analyze, and extrapolate as well. Calculating your return on initial investment before starting down this path is highly recommended.
-
Data Preprocessing
Data preprocessing is the segment of the data science project life cycle which is dependent on the type of data you have on hand. Images, audio, and video will take different times and resources (tools, software, staff) to properly analyze compared to financial records for example. Data preprocessing will ensure that your data is sorted and ready for analysis and deliver tangible data to your development team.
Data scientists need to treat this step of the life cycle with care and attention, as miscalculations can cost the company precious resources. This will require either complete re-analysis of entire data repositories or guesswork, both of which are bad signs that something is wrong. Data scientists involved in data preprocessing should check the data’s validity, detect inconsistencies, and consult project leads and other data analysts on how to proceed.
The exact reason to perform data preprocessing is to turn multimedia data content into numeric and empiric values. These values can be understood by AI algorithms and make project development more manageable. The process also serves to clean up any available data to make sure that it is useful to developers and testers later on.
While this may seem like an excessive amount of preparation, developing a solid data science model is all about prep work. A stable life cycle foundation will lead to a more precise, faster, and productive turnaround time for upcoming projects. Once the data has been processed and turned into computer data values, modeling and proof of concept development can start to manifest.
-
Proof of Concept (POC) Development
Another useful step in the data science life cycle model is to prepare a proof of concept (POC) before entering full development. A proof of concept is a pilot or a prototype that showcases how successful your initial data processing and findings are. While not critical, this part of the process will confirm that your data scientists are on the right track with the data they’ve processed. Here are the steps you may find useful in your pursuit of POC:
Modeling technique
There are several modeling techniques your data scientists can use to develop a proof of concept. The choice depends entirely on the type of product you are developing and the data you’re working with. These are separated into two distinct categories:
-
ML models – Random Forest, Ensembles, KNN, etc.
-
Deep learning models – GANs, RNN, LSTN, etc.
Test design
With a modeling technique chosen, you can develop a test design to apply the data you’ve collected too. This will minimize your developers’ errors and allow you to spot any lingering data inconsistencies before production.
Model building
Developing a model which your team can use in production will require you to use a modeling tool everyone on the development team agreed on. You will need to set the exact parameters to follow, as well as rely on the models recommended by the modeling tool you chose. Create a cohesive report on the models which you’ve developed and interpret their results to your development team. Elaborate on any misunderstanding they might have on the results of your POC and their work will be that much easier as a result.
-
Review and Evaluation
Once your POC is developed and analyzed, you should take your business goals and project milestones into consideration and compare them. You can mine for more data that way to ensure that what you’re working with is tangible and applicable. Perform a model assessment to sum up the results of your findings so far and revise your parameters for the data science life cycle if needed. Do this until you are satisfied with the model you came up with and document it. This model can then be used and reused as many times as you need in the context of your business’ workflow. Data scientists employ various techniques to check the accuracy of the data they’ve analyzed before handing it over. Here are some of the methods you can use:
-
The confusion matrix is used to compare different data classes to numbers of instances. They are used to detect false positives in your dataset, ensure the model’s accuracy, and sensitivity to new and unverified datasets being inserted.
-
Lift and gain charts are used for targeting the right customers during the marketing or a sales campaign. They are very useful in determining how likely a new audience is to respond to your content, for example, given your past performance.
-
Cross-validation represents separating data into multiple parts to present you with a model performance measurement. This is a comprehensive data evaluation method that tests and retests data multiple times.
-
ROC curve is used to gauge the ratios between false positives and true positives in your datasets. This is useful for determining the rate at which you discover or generate false positives, signaling that something is wrong in your POC.
The choice of method should always fall to whatever your business needs are at the time. Factor analysis can be performed at this time to gauge how your POC model treats different data samples to double-check your findings.
-
Real-World Deployment and Monitoring
Full development can begin once all the concerned parties are satisfied with the initial modeling and testing results. The data model you’ve created can be applied to full-scale production and used in DevOps as a reference point.
Model, or models, should be prepared by senior developers or data scientists so that everyone involved in the production can use them autonomously. They should be delivered in the form of scripts, or as a custom UI element integrated into an existing software solution. Integrating a new data model will require some onboarding and assistance at first but the staff should be able to use it themselves relatively quickly.
-
Data Maintenance
Assessing and maintaining the data science model’s efficacy takes center stage after the model has been deployed. Model maintenance shouldn’t be overlooked, as new bugs and social engineering issues can crop up unexpectedly. The model can be built on and reiterated periodically to boost its performance further.
However, the reason to conduct maintenance is to make sure that the business’ workflow doesn’t suffer as a result of new data models being used. Sudden failure or constant hitches which impede the staff from doing their jobs are signs that something is wrong. Data maintenance can be performed both by data scientists and by a dedicated AI algorithm with different flags designed for detecting data model inconsistencies.
-
Data Disposition
As the last part of a data science project life cycle, data disposition involves the use and reuse of existing and newly generated data models. Data models which are found unsuitable for long-term implementation are deleted at this point and only the most high-performing ones remain.
Given that this is a “cycle”, the newly created data can be used to start the process of developing a new data model again. While this involves reusing some datasets multiple times, the new variables will more than make for that discrepancy.
Data deletion should be treated with extra care however as it involves total deletion of said data. Only the most useless and bloated datasets should be considered for full deletion, as many may still prove useful to your business. Data can be either overwritten with more useful datasets or physically destroyed in the case of HDDs and optical drives.
Many businesses do conduct full data deletion to maintain their clients’ privacy and to comply with their corporate information standards. This is necessary for many development outsourcing projects since corporate secrets being leaked put a bad precedent on the companies involved in the project. The choice of whether to delete data or not in a closed business environment is at the discrepancy of data scientists, project leads, and managers.
In Conclusion
With AI technologies being even more prominent as 2022 grows near, managing your project’s data life cycle will be more important than ever. Creating a reusable life cycle model for new projects will also speed up your production pipeline and lead to QA and testing more quickly.
The main obstacle which many businesses are still facing is the lack of proper talent when it comes to AI management. Such specialists are rare and most of them are already employed by large corporations who intend to retain them. Gauge your resources and consider integrating a data science life cycle into your business model and your workflow will transform for the better in 2022.