Комп’ютерний зір ̶ є новаторським. Дивовижним. Корисним.
Проте ми бачимо чимало проблем, з якими зіштовхуються компанії при розробці та впровадженні цієї технології. Знання цих проблем допоможе уникнути дорогих затримок проєкту та інших проблем.
У цій статті:
-
Визначення комп’ютерного зору
-
Причини, через які важко розробляти комп’ютерний зір
-
Поширені помилки при розробці та впровадженні програмного забезпечення для комп'ютерного зору
Що таке комп’ютерний зір?
Комп’ютерний зір ̶ це область штучного інтелекту (ШІ), що дозволяє комп’ютерам інтерпретувати значення цифрового контенту, наприклад зображень. Вона вчить їх розпізнавати об’єкти, що містяться в контенті, визначати їх характеристики та осмислювати показані ситуації, як це роблять люди.
Комп’ютерний зір ̶ це складна технологія, оскільки машини намагаються розпізнати значення контенту на рівні пікселів, проаналізувати його та інтерпретувати результати за допомогою спеціально розроблених програмних алгоритмів. У цьому сенсі можна сказати, що ця технологія намагається відтворити деякі частини людської системи зору.
Ось стисла візуалізація роботи комп’ютерного зору.
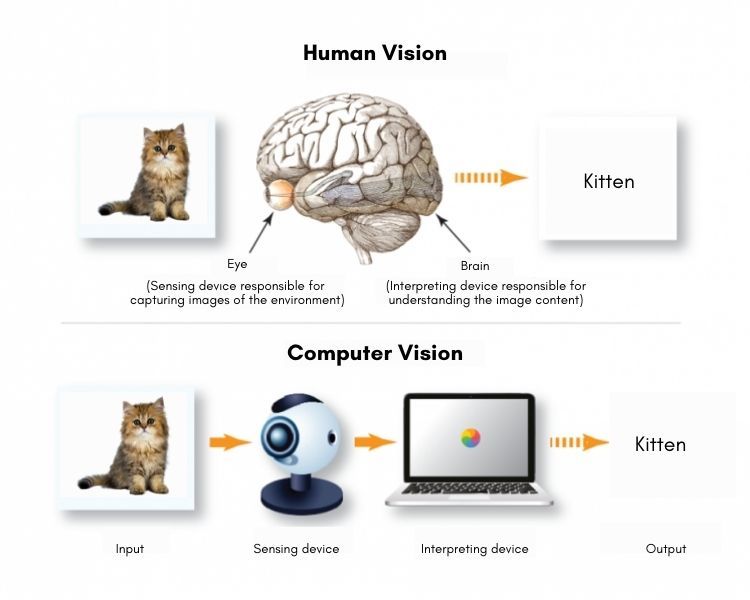
Комп’ютерний зір стає корисною технологією та вже застосовується в автономних транспортних засобах, відстеженні спортивних подій в режимі реального часу, програмах з перекладу, охороні здоров’я, виробництві та десятках інших галузей. Підприємства визнають велику цінність та переваги цієї технології в забезпеченні конкурентних переваг та інноваційних можливостей.
Але розробка та впровадження такої технології, як комп’ютерний зір, може бути досить складною задачею…
Чому комп’ютерний зір важко розробляти?
Комп’ютерна наука пройшла довгий шлях, щоб зробити можливими такі технології, як візуальний штучний інтелект (що, по суті, і є комп’ютерним зором). Однак розробка такого рішення, особливо готового до використання програмного продукту для бізнес-покупок, залишається досить складною задачею.
На це є кілька важливих причин, і їх розуміння є ключовим для створення чинного інструменту комп’ютерного зору.
Давайте розглянемо ці причини.
-
Інтерпретація контурів. Замкнуті контури відіграють вирішальну роль у системі зору людини. Вони дозволяють нам осмислити візуальну інформацію, групуючи нечіткі елементи об’єктів разом, щоб вони виглядали як структура, форма чи обрис. Відтворення такого самого надійного механізму інтерпретації залежить від багатьох процесів у мозку і залишається основною проблемою.
-
Упередженість людини пов’язана з інтерпретацією результатів. Як і у багатьох інших комп’ютерних системах, упередженість людини є проблемою, яка впливає на розробку рішень для комп’ютерного зору та спосіб інтерпретації цифрового вмісту.
-
Вивчення абстрактних взаємозв’язків між об’єктами. Людський мозок вміло розпізнає не дуже очевидні взаємозв'язки між предметами, елементами та формами. Ми можемо легко зрозуміти основні ідеї, що є проблемою для машин. У них немає перцептивного групування (того, як люди бачать та сприймають зорові об’єкти), робочої пам’яті та уваги.
-
Неповне розуміння системи зору людини. Хоча може здатися, що ця наука зрозуміла, реальність трохи інша. Нам ще багато чого потрібно дізнатись про людський мозок та про те, як він керує системою зору, тому існує багато «сірих зон» у дослідженнях.
-
Мінімально необхідна візуальна інформація, що потрібна для інтерпретації. Дослідження показали, що комп’ютерний зір не може пояснити чутливість людини до точних конфігурацій об’єктних характеристик, необхідних для інтерпретації. Як результат, машинам потрібно набагато більше візуальної інформації для створення осмислених інтерпретацій у порівнянні з людьми.
Разом ці причини визначають межі поточних рішень для візуального штучного інтелекту. Але знання своїх обмежень також допомагає зменшити їх вплив на рішення, які ми створюємо.
Першим кроком до досягнення цієї мети є розуміння того, як ці причини перетворюються на типові помилки, допущені під час розробки продуктів комп'ютерного зору.
Ось деякі найпоширеніші помилки.
П’ять найпоширеніших помилок при розробці та впровадженні комп’ютерного зору
Більшість компаній ризикують зробити ці помилки при розробці та впровадженні продуктів, заснованих на технологіях комп'ютерного зору. Знання цих помилок допомагає орієнтуватися в складностях та зменшити витрати на проєкт у довгостроковій перспективі.
1. Погана модель перетворення візуальної інформації
Ми знаємо, що люди та машини по-різному інтерпретують візуальний контент.
З одного боку, люди сприймають контент дуже інтуїтивно та швидко, без будь-якого перетворення, оскільки ми здатні зрозуміти його візуально. З іншого боку, є машини, інтерпретація яких відрізняється: вони бачать візуальний вміст як цифри, що являють собою пікселі.
Таким чином, замість інтуїтивного сприйняття зображення, машини проходять процес перетворення візуальної інформації: кодування. Цей процес для них досить важкий, оскільки їм не вистачає інтуїтивної здатності. Ось чому створення засобів з підтримкою комп’ютерного зору передбачає період, коли програмісти навчають моделі ефективно та швидко виконувати перетворення числових даних.
Для швидкого перетворення візуальна інформація розбивається на форми, які машини можуть сприйняти. Зазвичай це зображення, розділене на складові частини ̶ пікселі. Результат виглядає приблизно так, і кожен піксель несе в собі крихітну інформацію для алгоритму комп'ютерного зору.

Безкоштовне зображення: Джерело
Ефективність такої моделі, яка перетворює візуальну інформацію в числову, є важливим фактором, що визначає успіх продуктів комп'ютерного зору.
2. Погане виявлення відкритих та закритих контурів
Модель комп'ютерного зору повинна бути здатна вивчити поняття відкритих та закритих контурів, щоб визначити, чи містить їх зображення. Як ми вже розглядали цю тему раніше, люди мають природну здатність розпізнавати такі форми, тоді як машини цього не роблять.
Ось чому розробники моделей глибокого навчання, які керують комп’ютерним зором, повинні навчити їх виявляти відкриті та закриті форми в різних умовах. Це вимагає значних зусиль, але вже є купа прикладів добре навчених нейронних мереж, які легко розпізнають як прямі, так і криві лінії (зокрема, чудова розробка компанії Microsoft).
Отже, щоб переконатись, що комп’ютерний зір здатен розпізнавати замкнуті контури, компаніям потрібні відповідні спеціалісти для розробки навчальних наборів даних та усунення проблем, що виникають. Наприклад, однією з найбільш поширених проблем є виявлення фігур, коли вони збільшуються в розмірах.
3. Абстрактне візуальне міркування
Це загальна проблема, яка виникає через нездатності нетренованого алгоритму комп’ютерного зору зрозуміти взаємозв’язок між об’єктами та формами на зображеннях. Простими словами, алгоритм потрібно навчити виявляти зв’язки між об’єктами, щоб допомогти користувачам зрозуміти, що відбувається на зображенні.
Хоча ця задача надзвичайно легка для людини, для її рішення необхідно використати навчальні набори даних з великою кількістю зображень для тестування. Якість тестування визначає, наскільки хорошими будуть можливості алгоритму до абстрактного візуального міркування.
4. Апаратні обмеження
Запуск програмного продукту для комп'ютерного зору вимагає великої обчислювальної потужності. Особливо це стосується додатків у режимі реального часу, оскільки їм потрібно обробити та зберегти набагато більше даних. Це означає, що потрібно залучити значну кількість апаратного забезпечення.
Візьмемо за приклад рішення для моніторингу в режимі реального часу. Така система призначена в першу чергу для аналітики та розпізнавання обличчя, причому обидва направлення вимагають постійної роботи. Але типова система моніторингу включає сотні, якщо не тисячі камер, кожна з яких генерує десятки зображень в секунду.
Окрім камер, така система моніторингу потребує передачі, аналізу та зберігання даних. Все це перетворюється на апаратне забезпечення. Підприємства використовують хмару для обробки та зберігання даних, що допомагає зменшити загальні витрати, але для досягнення поставлених завдань їм все одно потрібна професійна допомога.
Якщо компанія використовує команду розробників машинного навчання, вона може отримати масштабований додаток комп'ютерного зору, що зменшує вимоги до обладнання та загальні витрати. Для цього вони застосовують найновіше обладнання для штучного інтелекту та прискорювачі, оптимізовані для роботи з великими об’ємами даних.
Отже, незалежно від можливостей обробки даних або випадків використання, індивідуальний підхід до розробки із залученням професійних розробників машинного навчання повинен допомогти створити гідну модель комп'ютерного зору для вашого бізнесу.
5. Комп’ютерний зір для відео
Більшість програм комп’ютерного зору зосереджені на розпізнаванні об’єктів на зображеннях. Відсутність обчислювальних ресурсів та потужності призвело до того, що ця технологія зосередилася на обробці лише зображення, а це означає, що робота з відео ̶ це зовсім інша історія.
Незважаючи на те, що ця технологія продовжує вдосконалюватися, коли мова заходить про відео, їй ще потрібно пройти довгий шлях. Рух ̶ це досить складна річ для відстеження, тому вчені та розробники даних все ще працюють над методами досягнення цієї мети.
На даний момент відео моделі комп’ютерного зору досить хороші для практичного застосування, але вимагають професійних знань, щоб забезпечити компаніям всі переваги.
Рішення для комп’ютерного зору: висновок
Комп’ютерний зір ̶ це одночасно, захоплююча нова технологія та перевірений спосіб створення популярних продуктів та послуг. Хоча розробка та впровадження візуальних рішень для штучного інтелекту може здатись складним завданням, ми перебуваємо на тому етапі, коли знаємо достатньо, щоб це працювало.
Ось чому продукти з використанням комп’ютерного зору, такі як автономні машини, програми для перекладу та системи спостереження, стали реальністю. Однією з основних причин, чому ми можемо використовувати ці речі, є знання того, як подолати перешкоди у створенні справжнього візуального інструменту штучного інтелекту. За професійної допомоги будь-який бізнес може скористатися перевагами цього нововведення в своєму арсеналі.