Computer vision is groundbreaking. Amazing. Useful.
Yet, we see quite a few troubles that businesses face when developing and implementing this technology. Knowing these issues is a good idea to avoid costly project delays and other problems.
In this guide:
-
Computer vision definition
-
Reasons why computer vision is difficult to develop
-
Common mistakes in computer vision software development and implementation
What is Computer Vision?
Computer vision is a field of Artificial Intelligence (AI) that enables computers to interpret the meaning of digital content like images. It teaches them to recognize the objects present on content, define their characteristics, and make sense of the shown situations like humans do.
Computer vision is a complex technology, as machines try to recognize the meaning of content at a pixel level, analyze it, and interpret results using specially-made software algorithms. In this sense, we can say that this technology is trying to replicate some parts of the human vision system.
Here’s a quick visualization of how computer vision works.
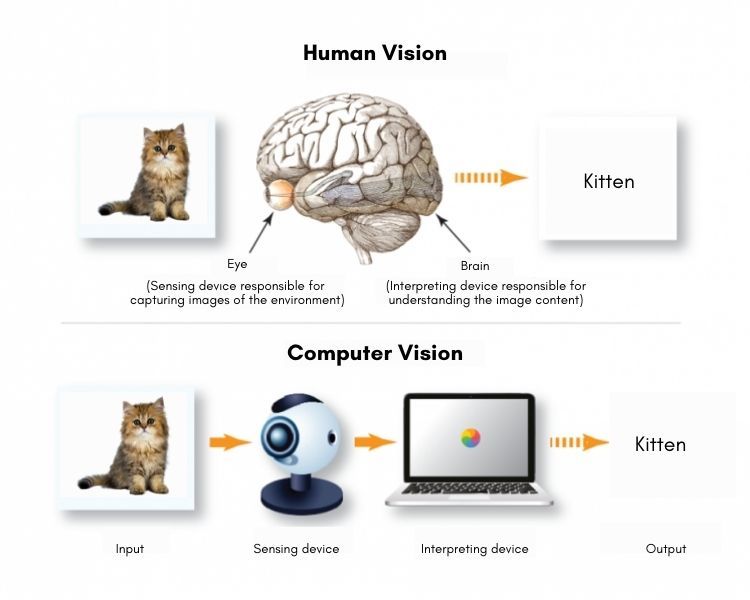
Computer vision is becoming a useful technology and is already applied in autonomous vehicles, real-time sports tracking, translation apps, healthcare, manufacturing, and dozens of other fields. Businesses recognize the great value and benefits of this technology in providing them with competitive advantage and innovation opportunities.
But developing and implementing technology like computer vision could be quite challenging...
Why Is Computer Vision Difficult To Develop?
Computer science has come a long way to make technologies like visual AI (which is what computer vision is, essentially) possible. Still, developing such a solution, especially a ready-to-use software product for business purchases, remains quite challenging.
There are several important reasons for this, and understanding them is key to creating a working computer vision tool.
Let’s go through these reasons now.
-
Interpretation of contours. Closed contours have a critical role to play in the human vision system. They allow us to make sense of visual information by grouping indistinct elements of objects together to appear as a structure, form, or shape. Replicating the same robust interpretation mechanism relies on many processes in the brain and remains a major challenge.
-
Human bias related to the interpretation of results. As with many other computer systems, human bias is an issue that affects the design of computer vision solutions and the way it interprets digital content.
-
Learning abstract relationships between objects. The human brain is proficient at recognizing not-so-obvious relationships between objects, elements, and shapes. We can understand underlying ideas easily, which is a problem for machines. They don’t have perceptual grouping (the way humans see and organize visual objects), working memory, and attention.
-
Incomplete understanding of the human vision system. Although it might seem that science has figured this one out, the reality is a bit different. We still have a lot to learn about the human brain and how it manages the vision system, so there are many “gray areas” in research.
-
Minimally necessary visual information required for interpretation. Research showed that computer vision isn’t able to explain human sensitivity to precise object feature configurations required for interpretation. As a result, machines need much more visual information to generate meaningful interpretations compared to humans.
Together, these reasons define the limits of the current visual AI solutions. But, knowing our limits also helps to help lessen their influence on the solutions we create.
The first step to getting there is understanding how these reasons translate into common mistakes made during the development of computer vision products.
Here are some of the most common mistakes.
5 Common Mistakes in Developing and Implementing Computer Vision
Most businesses risk making these mistakes when developing and implementing products based on computer vision technology. Knowing them helps navigate complexity and reduce project costs in the long term.
1. Poor Visual Information Conversion Model
We know that humans and machines interpret visual content differently.
On the one hand, humans perceive it very intuitively and quickly without any conversion because we’re able to understand them in a visual manner. On the other hand, there are machines whose interpretation is different: they see visual content as numbers representing pixels.
So, instead of perceiving images in a visual manner intuitively, machines go through the process of conversion of visual information: encoding. This process is quite hard for them, as they lack that intuitive capacity. That’s why the creation of computer vision-enabled tools involves a period where programmers train models to perform numerical conversion effectively and quickly.
To accomplish a fast conversion, visual information is broken down into a form that machines can read. Typically, it’s an image divided into its building blocks: pixels. The result looks something like this, and each box represents a tiny piece of information for the computer vision algorithm.

Free image: Source
The effectiveness of such a model that converts visual information into numerical is an important factor that defines the success of computer vision products.
2. Poor Detection of Open and Closed Contours
A computer vision model should be able to learn the concept of open and closed contours to tell if an image contains them. As we touched upon this topic earlier, humans have a natural ability to recognize such shapes, whereas machines do not.
That’s why developers of deep learning models that drive computer vision must train them to detect open and closed shapes under a variety of conditions. This requires significant effort, but there are already a bunch of examples of well-trained neural networks that recognize both straight and curved lines easily (the one developed by Microsoft, in particular, is a great one).
So, to ensure that a computer vision has what it takes to detect closed contours, businesses need appropriate expertise to develop training datasets and fix issues as they arise. For example, one common issue is detecting shapes when they become larger in size.
3. Abstract Visual Reasoning
This is a common struggle that stems from the inability of an untrained computer vision algorithm to understand the relations between objects and shapes in images. In simple words, an algorithm needs to be taught how to detect connections between objects to help users make sense of what’s going on in an image.
While super easy for human observers, this task involves using training datasets with numerous images for testing. The quality of the testing defines how well the algorithm’s abstract visual reasoning capabilities will be.
4. Hardware Limits
Running a computer vision software product requires a lot of processing power. This applies specifically to real-time applications because they need to process and save much more data. This means that there’s also a considerable amount of hardware involved.
Let’s get a real-time monitoring solution as an example. Such a system is designed primarily for analytics and facial recognition, both of which require continuous operation. But, a typical monitoring system includes hundreds, if not thousands of cameras, with each generating dozens of images per second.
Besides cameras, such a monitoring system needs data transfer, analysis, and storage. All of this translates into hardware. Businesses use the cloud for processing and storage, which helps to reduce the overall cost, but they still need professional assistance to achieve their tasks.
If a business uses a team of machine learning developers, it can receive a scalable computer vision application that reduces hardware requirements and overall costs. They do so by applying the latest AI hardware and accelerators that are optimized for data-intensive uses.
So, regardless of the data processing capabilities or use cases, a custom development approach involving professional machine learning developers should help create a computer vision model worth your business.
5. Video Computer Vision
Most computer vision applications focus on recognizing objects in images. The lack of computing resources and power led this technology to focus on single image processing, which means working with videos is a different story.
Although this technology is continuing to improve when it comes to videos, it still has a long way to go. Motion is a pretty complex thing to track, so data scientists and developers are still working on methods to achieve this goal.
At this point, video computer vision models are good enough to be practical, but require professional expertise to provide businesses with all the benefits.
Computer Vision Solutions: Summary
Computer vision is both an exciting new technology and a proven way to create popular products and services. Although developing and implementing a visual AI solution could be difficult, we’re at the point where we know just enough to make it work.
That’s why computer vision-enabled products such as autonomous cars, translation apps, and surveillance systems are a reality. One big reason why we can use these things is knowing how to overcome the hurdles of creating a true visual AI tool. With professional help, any business can enjoy the benefits of having this innovation in its arsenal.